Random Forest Classifier
The Random Forest Classifier is a meta estimator that fits a number of decision tree classifiers on various sub-samples of the dataset and uses averaging to improve the predictive accuracy and control over-fitting.
The Random Forest Classifier Model came out with the following results
Training Data Score : 100% - Testing Data Score : 97.17%
True Positive : 97% , False Positive : 2.7% , False Negative : 3% , True Negative : 97.3%
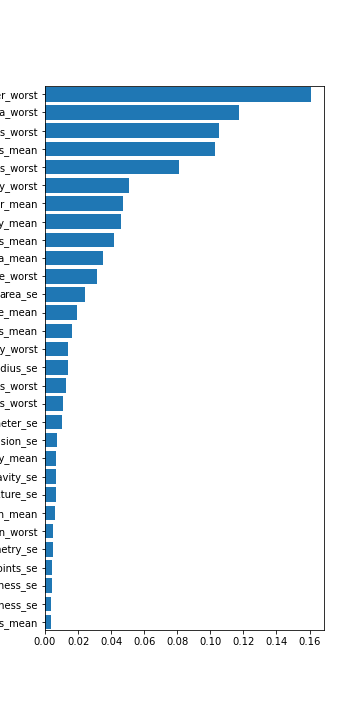
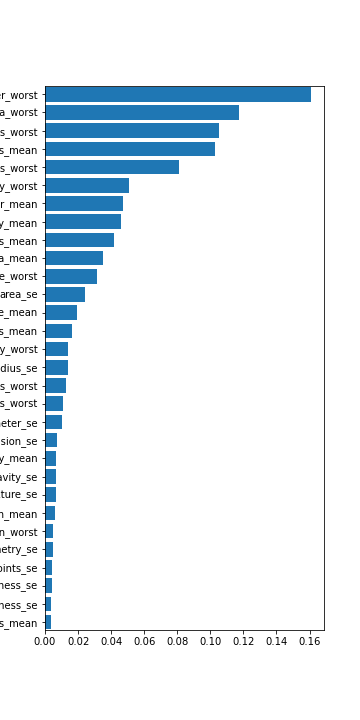
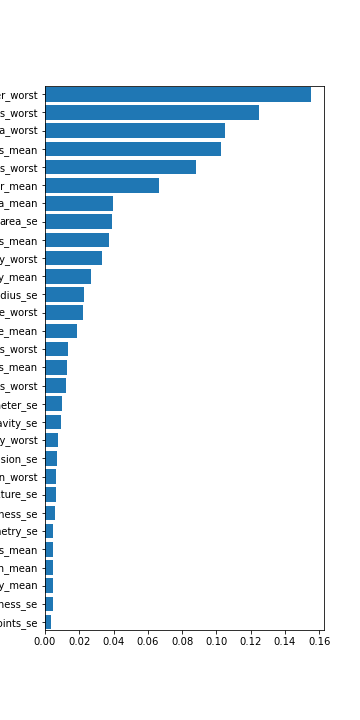
The random forest classifier tends to be good at binary classification problems and proved such during our study. We also tested it with the modified datasets for balancing. On average we got better results than the logistic regression, but not always and not as often as we might have guessed. Again the full dataset tended to outperform. For the random forest we also chose to look at the features it picked out as important and plotted them out. We found about only 14-15 features that looked significant. The random forest full dataset tended to give an accuracy of 97% - 98%, just like the logistic regression. On the other hand the balanced datasets did outperform in terms of giving a lower false negative rate: 3% for the normal and only 1.5% for the balanced.