K-Nearest Neighbors
The K-Nearest Neighbors (KNN) algorithm is a data classification method for estimating the likelihood that a data point will become a member of one group or another based on what group the data points nearest to it belong to.
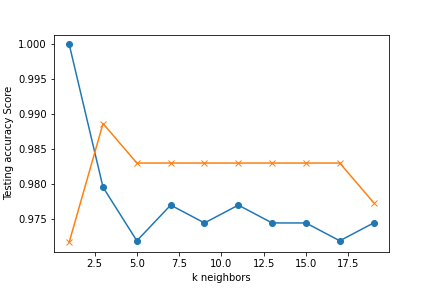
The K-Nearest Neighbors Model with a k-value of 3 came out with the following results
Training Data Score : 97.7% - Testing Data Score : 98.3%
True Positive : 110 , False Positive : 1 , False Negative : 2 , True Negative : 64
In the K-nearest neighbor model we ran the standard test to find the optimal value of k. We found that 3 gave us surprisingly good results. We could even say of the supervised classification algorithms we tried we were quite unexpectedly impressed with how well this did since we would not necessarily think of it as doing well for this type of problem. We very consistently got accuracies in the 98% though it did still suffer the same 3% false negative rate.